Building a Scrapy Spider with Python (for Trip Advisor)
Good morning to everybody, today is a great day, because we are goanna learn how to build the faster crawler I can build in Python, with the only help of Scrapy, an open source and collaborative framework for extracting data from websites.
I know you want to get immediately in the middle of the action; but before to begin, I invite you to read this article where I explain the difference between scrapy and the other tools available in python to crawl the web. Basically, Scrapy is the tool that allow making fastest scraper… on the other hand is not properly user friendly…
…but here is where I am!! Going to help you in this!
In this guide I will refer to the tutorial in here. So, first thing to do is to initialize a project (remember first to install scrapy with pip). Suppose the name of the project will be “TripAdvisor” (my demonstration will be implemented over the site). Open the cmd, go in the folder where you like your project to be, and run the command :
scrapy startproject TripAdvisorThe command will create a directory with the following contents:
TripAdvisor/
scrapy.cfg # deploy configuration file
TripAdvisor/ # project's Python module, you'll
import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your
spiders
__init__.pyAs you can see there is a particular folder called “spiders”, and there we are going to create our crawlers (the “spiders”).
Let’s create a simple one. Ok first thing to do… is to define the goal.
Personally, I have been pushed to learn scrapy at university. In the course of “social network analysis”, it was required to build a crawler and scrape the web, with the purpose of building a connected graph and analyze it.
Truely the theme was really open, in the sense each student can select a different web network and scrape it to build the network he prefer. The only requirements it was to have an enough big network at the end (at least 15.000 nodes), and this is the reason why I used scrapy at the end: to download a similar quantity of information, it requires a lot of time. Beacause fo this, it was preferable to have a quick enough crawler.
For what concerns the subject of the project, my election fell on Trip Advisor, the famous social network hosting millions of reviews about restaurants, hotels, attractions, etc…
I hope to write as soon as possible an article about this little research I carried out for the universitary project. But for the moment(and for the whole story), we will concentrate in retrieving information about restaturants…

In particular, we will concentrate in finding information about restaurants of a specific locality. Just for this time we will use as example the city of “Sassari” (I’m from there, in Sardinia for those who do not know). So, search “Sassari” on Trip Advisor, select the restaurants page, and let’s explore the web page in order to understand what kind of items we are interested in, and what kind of information we will be able to gather.
Ok, probably you need to scroll a little down the page to reach the point in the image. Restaurants are sort in order of customer preferences from the most rated with number “1” to the last. At the time of writing this article, the site told me that there were 379 results matching my filters. This 379, is referring to the number of items I want to gather (the restaurants in the city of Sassari).


At the bottom of the page, we discover that restaurants are distributed in pages, more precisely there are 30 restaurants per page. Good to know it. If we want all the restaurant, our spider will visit all these pages ( 379 / 30 means the spider will visit 14 pages).
Now let’s look at the URL:
https://www.tripadvisor.com/Restaurants-g187885-Sassari_Province_of_Sassari_Sardinia.html
Usually when using web scraper, we need to have this sort of base URL. And if we need to scrape more pages, we want to understand how to generate next URLs (page 2, page 3, etc…). In order to do this, go to the second page and observe the URL. You will note it’s the same as the base URL. If you are asking yourself why, know that for sure the number of the page is getting called by a parameter on the request. You can try to get it by inspecting the network panel on the developer tool of the browser, or even by analyzing the element (see below).

But luckily, we do not need to do that. If you paid attention while exploring the web page, you noticed that there is a next button at the bottom right of the page. We can examine even that.
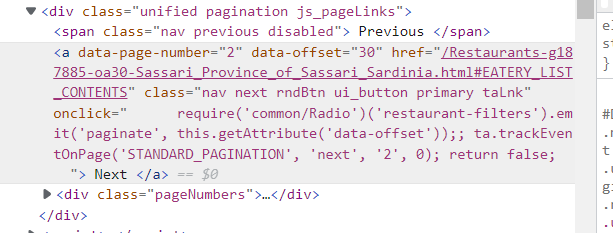
From our scrapy spider, we will use exactly that button. As you can see the request is practically the same, but it allows us to explore the next link from each page without caring about the page number. We will obviously start from the first one page, for which we already have the URL.
Ok regarding the URL. It is now the moment to start analyzing the html and the ways to isolate information we are interested in.
But first, let’s take a little breath…
…you need to understand something more regarding the scrapy spiders.
Below the example from the tutorial:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'https://quotes.toscrape.com/page/1/',
'https://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
self.log(f'Saved file {filename}')Important things to note is to understand the three elements that are defined in the class declared:
- name: is the alias with which you will call the spider from the cmd;
- start_request: is a function that defines how to iterate over a bunch of urls/objects; it works as a generator;
- parse: is the method in charge of defining how to parse the content; it can be balled by the command line
This file spider should be located in the spider folder. The name of the file however is not too much important. The spider will be started from command line by running:
scrapy crawl quotesN.B. it uses the name we gave to the spider
Below my example:
import scrapy
class geoRestaurantsSpider(scrapy.Spider):
name = "geoRestaurant"
def __init__(self, url=None, *args):
super(geoRestaurantsSpider, self).__init__(*args, **kwargs)
self.start_urls = [f'{url}']
def parse(self, response): for div in repsponse.css:
...
...
yield {...} next_page = response.css(...).attrib['href']
if next_page is not None:
yeld response.follow(next_page, callback=self.parse)
For the moment accept the dots as arguments 🥲
The init function in this case it’s important, we are going to use cmd arguments to indicate the base URL. It is possible to implement a similar solution by using the kwargs.
You can even indicate an output file using the option “-O” for a new file, or “-o” to append the content to an existing file. These two are default scrapy spider parameters.
scrapy crawl geoRestaurant -a url=http://www.tripadvisor.com/...The parse method yields each parsed restaurant item found in the response (the page required by the URL). After that, it calls itself using the method response.follow(). This method allows to declare what to do. In this case it passes the URL “next_page” to the self.parse function declared as callback.
The scrape will stop only when the next button does not exist anymore (if it is None).
Returning to us… now you understood the structure of a basic spider 🤞 Giving that, the remaining part it will be a piece of cake. It will be more or less exactly like all other scrape contexts. Scrapy allows two use two different selectors: xpath and/or css selector.
You can use selectors directly on the whole web page by response.css(), or either on any element selected by a previous selection.
div = repsonse.css("div.class")
myelement = div.css("span.aclass.nth-child(2) > span) To get the element “myelement” it can equivalent in this case to write:
myelement = div.css("div.class > span.aclass.nth-child(2) > span)To understand the syntax of the selectors, look at the documentations. In my scraper I used only the CSS selector. Find the documentation at: CSS Selectors Reference (w3schools.com). But feel free to use the selector you prefer.
Another important concept you should get, is the method get() …pun intended! It returns the first element of the page that match the selection. Yes, because on each page there can be more elements, even a lot that match a selection. To have the list of them you need only to use getall() instead of get(), it will return all of them.
And getall() will be a first step in the selection. In fact, inside the parse method I want to select and iterate all the 30 restaurants contained on each page. So how to find the selection?
Go in the page, right click on the element you are interested in, and from the appeared menu select “inspect ”, in order to open the source of the page for that element.
In my case I discovered the div containing the restaurant have a specific class (“YHnoF”). However, some of these items, are not enlisted as normal restaurants, but they appear repeated as sponsored restaurant. I find how to ignore this: they have an attribute called “data-test”, with the value “SL_list_item”. So I will iterate over the element in this way:
for div in response.css('div.YHnoF'): if div.css('::attr(data-test)').get() != 'SL_list_item': ...
Now let’s look in deep at what we can retrieve. First of all, it can be interesting to have the name of the restaurant, the URL of its page (for further analysis maybe 😜), the score (the customer evaluation in stars), the price (indicated by the number of “$”), the number of reviews, and more.
Sometimes it is really easy to get the desired element.
For example, to get the number of reviews, I find the element type and its class, and it was sufficient to identify the element inside the div. I wrote this in my code:
try:reviews=int(div.css("span.IiChw::text").get().replace(',', ''))except:reviews=0
The wording ::text is used to get the text contained inside an element.
Sometimes it is really tricky.
As in the case of the price, for which there were more div and span with the same classes, and so it was complicated to get the right one.
div.css("div.bAdrM > span.qAvoV:nth-child(2) > span::text").get()In order to have this I use the inspect button together with the option “copy selector” in the developer tools.
But you need to test your selector. And you cannot think to debug your spider just running the crawler each time from the cmd…
Fortunately, a tool provided by Scrapy comes to our aid: the Scrapy Shell.
Open the Scrapy Shell from the prompt:
scrapy shellRun the command above to request a web site:
fetch("https://www.tripadvisor.com/Restaurants-g187885-Sassari_Province_of_Sassari_Sardinia.html")Now the content of the page is saved on a “variable” called “response”, and you can start trying your selector on that. In our case, first thing to do is to save on a variable the whole content of a single restaurant:
div = response.css("div.YHnoF")[4]I used the number 4 just to select a random item from the list. Remember in fact, that in this case the selection matches 30 elements as well. However, at this point we can start playing with the shell and discover the right selection for our elements.
(506) Trip Advisor Scrapy Spider — YouTube
Right click on an element -> inspect it -> the developer tool should be open now, find the right element you are looking for -> right click on it -> copy the selector -> te game is done.
In the shell you can start testing the efficiency of the selectors you evinced from the web page by inspecting the source code. From now on …you can start adding the elements to your spider.
Unfortunately, there are some occasions in which all this procedure could not work. For example, I was trying to fetch by code wether a restaurant is taking safety measures for covid and weater not (there is a sort of badge in the item). I inspected the element and copied the css path…. however, no way to find the element by the scrapy shell. To verify if that is present, you can even try to get all the text inside the selected “div” and see there is not a string “Taking safety measure”. It should be dynamicaly agenerated content, wrote by a js function and not present on the html dometree.
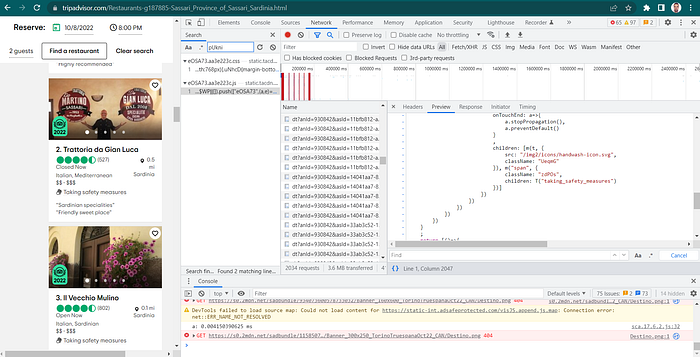
I will write about how to scrape js contents in another article maybe. For the moment I show you in my screenshot, that using the network panel of the development tool and searching for the class I found the right request…. however, we need more tool in our spider in order to manage a thing such this. Let’s postpone it and approach the conclusions instead.
There is one last thing you need to understand. Inside the method parse, when you use the Python yield you pratically add to the scraped list the argument passed to the “yield”. Each time I call yield, I add a new restaurant to the scraped information. What argument am I passing? I’m yelding a python dictionary, with all the information I retrieved within the spider. Keys of the dictionary will be the columns of my output (if it is a csv file).
Ok we have the output; I think it can be enough for today. So, try to use my suggestions to build your own spider and enjoy in scraping the web.
At last, but not least… I leave you my spider code here.
Thanks for the attention and stay tuned !!!
BYE
P.S. Follow 4 more ;)